PII data redacting in-house based on the detection result from Amazon Comprehend
Introduction
From the previous blog post, We've learned about the redaction of the data, how Amazon Comprehend deals with redaction of the data, as well as we've played around with redacting some example documents via AWS dashboard.
Let's come back to our rails application with notes. We've already can detect PII data, now we need to label them, as well as redact the data at the end. We've already known how to do it with Amazon Comprehend, but we don't necessarily want to add extra complexity to our application, and create each and every txt file for our notes records, and later on the process the output file.
Fortunately, we've already had everything in place, to make redaction in-house with Ruby.
The goals of this post are:
- Found out which words were detected as PII data, and to which entity types were labeled.
- Redact the PII data.
General content
In one of the last posts, we ended up on PII data detection. The result of the detection was as follows:
Based on the above results we can:
- As we have both begin and end offsets, we can find the word, which was detected as PII data, simply by calculating the difference between offsets.
- As we will find the word, we can easily redact them via operations on string with Ruby (or only based on offsets).
PII data redacting
First thing first, let's create a method to calculate the difference between offsets for each and every entity:
Secondly, we would like to know which word was detected as PII data, so we can simply accomplish it by:
Now let's build a method, which will return information about the entity name, and entity_type, so we later use this information.
Finally, we can take care of the redaction process.
In the above code, we're simply producing a shallow copy of note content, to avoid updating the original note content. Next, for each and every detected entity make a redaction, based on the offset, we masking the PII data with asterisks.
In the end, our service could look like this:
The whole source code for this blogpost could be found here. I've adjusted the application view a little bit, so we can see the result after the note is created. Below you can see the result:
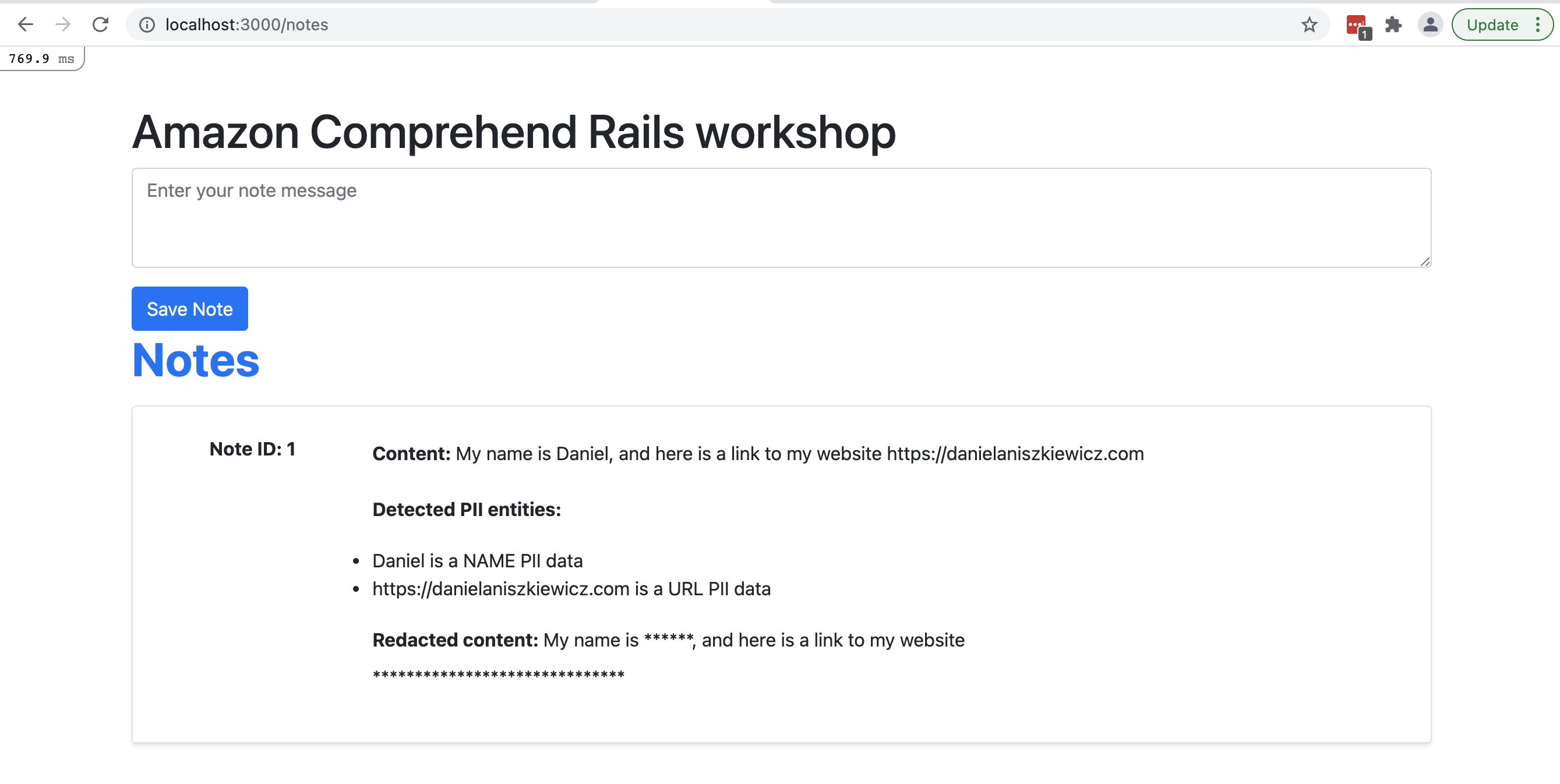
Summary
In this blog post, I've shown how to approach redaction in-house your application, based on the Amazon Comprehend PII detection results. In the end, you can the results. There a lot of approaches to detect, label, and redact the PII data as well. It all depends on your objectives. Another good approach would be to block the creation of a record during validation, and inform the user that they cannot add a note because it contains sensitive data.
In the approach I took, the note is always saved and we have both the original note and the edited note in the database. In various cases, employee supervisors can check what data has been detected as sensitive, who uploads it most often, and what type of PII data is most often uploaded.
For this application, I saw no need to use data redaction using Amazon Comprehend. This would be helpful for the large number of documents that would need to be analysed. For the purposes of this simple application, editing this in-house, was the optimal choice.
If you wouldn't want to mess around with offsets, there is also the option to use the endpoint detect_entities API (link here) which returns the type, and text directly. These are not necessarily PII types. Additionally, this is not the most optimal solution, as it requires an additional request to the API.
Objectives have been met:
- We've implemented methods to help find which words were detected as PII data, and to which entity types were labeled.
- We've redacted the PII data in-house with Ruby operations on string.
- We've learned different ways on how we can approach PII redaction.